
Tänk om du skulle översätta en mening från engelska till franska och du bara kunde läsa ett ord i taget, och när du kom till nästa ord var du tvungen att glömma det du precis hade läst. Detta var i huvudsak utmaningen som AI-språkmodeller stod inför före 2017. Det var då en grupp forskare vid Google släppte en rapport med titeln "Attention Is All You Need", och allt förändrades.
Den rapporten introducerade Transformern – den arkitektur som har blivit arbetshästen för nästan alla kraftfulla AI-språkmodeller du har hört talas om, inklusive ChatGPT, Google Translate och den AI-assistent du kanske läser detta genom i just detta ögonblick.
1 Problemet med det gamla sättet: RNN:er
Det populära tillvägagångssättet för språkuppgifter före Transformern var en mekanism känd som ett Recurrent Neural Network, eller RNN (även populärt känt som LSTM – Long Short-Term Memory). Konceptet bakom RNN:er är ganska enkelt: läs en mening ord för ord och bär med dig ett minne av det som redan har lästs när du fortsätter framåt. Det fanns dock några avgörande brister i denna design.
För det första var det långsamt. Eftersom RNN:er arbetar på varje ord sekventiellt kan man inte påskynda saker genom att köra beräkningar samtidigt. Det är som att ha 100 matematikproblem att lösa men bara få arbeta på ett i taget, även när det finns 100 miniräknare som står precis framför dig.
För det andra var långtidsminnet dåligt i RNN:er. När en mening är lång och ett ord mot slutet förlitar sig på något som sa i början, glömde RNN:en ofta bort det tidigare sammanhanget när den nådde den punkten. Detta är också känt som vanishing gradient-problemet – signalen från tidiga ord tonas ut innan den når slutet av sekvensen.
Detta innebar att de mest högpresterande RNN-modellerna slog i ett prestandatak. Något nytt krävdes.
2 Introduktion av Transformer: Attention Is All You Need
Transformern förkastade återkoppling (recurrence) helt och hållet. Istället för att läsa ord efter varandra och bygga en kedja av minne, tittar den på alla ord samtidigt och beräknar vilka ord som ska "pay attention" (fästa uppmärksamhet) vid vilka andra – därav namnet.
Den viktigaste innovationen kallas self-attention (även känd som scaled dot-product attention). Intuitionen här är att när man läser meningen ”Djuret gick inte över gatan eftersom det var för trött”, kan en mänsklig läsare omedelbart inse att ”det” syftar på djuret, inte gatan. Self-attention tillåter modellen att göra samma sak – den mäter relevansen av varje ord till alla andra ord i meningen samtidigt.
Matematiskt konstruerar modellen tre saker för varje ord: en Query (vad letar jag efter?), en Key (vad har jag att erbjuda?) och ett Value (vilken information bär jag faktiskt på?). Genom att jämföra queries och keys över alla ord producerar modellen attention-poäng som visar i vilken utsträckning varje ord påverkar förståelsen av alla andra ord. Detta åstadkoms på en gång – ingen väntan, inget glömmande.
3 Multi-Head Attention: Att titta från flera vinklar
Multi-head attention är ett av de smarta knepen Transformern använder. Istället för att utföra denna attention-beräkning bara en gång, utför modellen den flera gånger parallellt, varje gång med ett något annorlunda inlärt perspektiv. Föreställ dig åtta olika läsare, som var och en uppmärksammar en annan aspekt av meningen – grammatik, betydelse, ton, ordförhållanden – och sedan kombinerar alla sina insikter.
Den ursprungliga rapporten använde 8 parallella attention-huvuden. Detta gjorde det möjligt för modellen att fånga mycket rikare mönster än vad ett enskilt perspektiv någonsin skulle kunna.
4 Encoder och Decoder
Hela Transformern består av två huvudkomponenter: en encoder och en decoder.
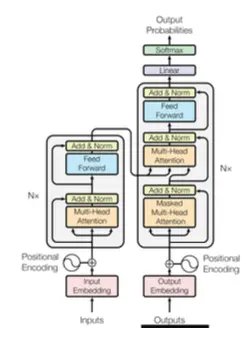
Encodern tar in indata (till exempel en engelsk mening) och bygger en djup förståelse för den. Den tillämpar self-attention så att varje ord fritt kan referera till varje annat ord. Tänk på det som en noggrann läsare som absorberar hela betydelsen av en text innan den svarar.
Decodern producerar utdata (en fransk översättning) ord för ord. Men till skillnad från en RNN kan den fortfarande se tillbaka på allt som encodern har lärt sig. Den innehåller också ett speciellt maskat self-attention-lager som hindrar modellen från att "fuska" genom att titta framåt på framtida ord som den ännu inte har genererat.
Tillsammans är encoder-decoder-arkitekturen det som gör Transformern så kapabel vid sekvens-till-sekvens-uppgifter – översättning, sammanfattning och frågeställning.
5 Positional Encoding: Att lära modellen om ordningsföljd
Det finns en hake: eftersom Transformern läser alla ord på en gång vet den inte automatiskt i vilken ordning de förekommer. Utan någon känsla för position skulle fraserna ”hund biter man” och ”man biter hund” se identiska ut.
Svaret är positional encoding – en matematisk signal som läggs till i representationen av varje ord och som berättar för modellen var i sekvensen det ordet sitter. Den ursprungliga rapporten använde sinus- och cosinusvågor med varierande frekvenser för att koda position. Det är ett litet men viktigt trick som gör att Transformern kan förstå ordföljd även när den bearbetar allt parallellt.
6 Varför detta revolutionerade AI
Fynden var häpnadsväckande. Den ursprungliga Transformern satte ett nytt rekord på översättning från engelska till tyska och överträffade alla tidigare modeller – inklusive de som använde ensembler av många modeller som arbetade tillsammans – samtidigt som den tränades på bara 3,5 dagar på 8 GPU:er. Tidigare state-of-the-art-modeller var mycket långsammare och mycket dyrare att träna.
Vad som är viktigare är att arkitekturen visade sig vara extremt anpassningsbar. Forskare upptäckte snabbt att man kunde använda bara encoder-delen (vilket gav modeller som BERT, som utmärker sig på att förstå text), bara decoder-delen (vilket gav modeller som GPT, som utmärker sig på att generera text) eller båda tillsammans (vilket gav modeller som BART och T5, som utmärker sig på översättning och sammanfattning).
Praktiskt taget alla moderna stora språkmodeller (LLM) är byggda på Transformer-arkitektur. Modeller som GPT-4, LLaMA och Gemini använder decoder-endast-designen, skalad till hundratals miljarder parametrar.
7 Den stora bilden
Transformern löste två samtidiga problem inom AI-språkmodellering: den möjliggjorde träning att bli dramatiskt snabbare genom parallellisering, och den gav ett mycket bättre sätt att förstå relationer mellan ord, oavsett hur långt ifrån varandra de visas i en mening.
En rapport, en arkitektur och en idé – att uppmärksamhet är allt du verkligen behöver – förändrade hela fältet för artificiell intelligens. Modellerna du interagerar med idag är direkta ättlingar till det genombrottet från 2017, och de har vuxit sig större, smartare och mer kapabla för varje år som gått.
Inte illa för ett nätverk som inte ens läser i ordning.
Referenser: Vaswani et al., ”Attention Is All You Need,” NeurIPS 2017. Hugging Face Transformers Documentation.

